回帰問題でのDropoutの悪影響とその対策
背景・目的
回帰問題をNNで解くときにDropoutとBatchNormを使わない方が良いという話を聞いた。
回帰問題をNNで解くときはドロップアウトとBatchNormは使わないほうがいいって話、あまり知られてない気がする
— Tsultra (@Tsultra_K) 2021年7月30日
Pitfalls with Dropout and BatchNorm in regression problemshttps://t.co/RNfCj5cqsB
Pitfalls with Dropout and BatchNorm in regression problems | by Søren Rasmussen | Towards Data Science
回帰問題でDropoutを使うことによる影響を検証し、その対策について検討する。
(BatchNormの検証はしていない。)
注意
汎化性能についての検証はしていない。
今回の検証結果では回帰問題でDropoutを使うことで悪影響があるという結論に至ったが、実際のタスクでは汎化性能向上による良い影響もあるという点に注意してほしい。
まとめ
- Dropoutによる悪影響
- 回帰問題でDropoutを使うと、正解値の絶対値が大きいときに推定値が小さくなる傾向があった。Dropoutの後に非線形層(ReLUなど)があるとその効果は特に顕著であった。
- 対策
- Dropoutの代わりにGaussianDropout, UniformDropoutを使うと悪影響がある程度改善された。
- MontecarloDropoutを使うと悪影響がなくなった。
- 考察
- 対策手法ではDropout適用後の分散の変化が小さくなる(と思う)ので、対策により結果が改善されたと考えられる。
- その他
- 分類問題ではDropoutを使っても悪影響はなかった。
感想
- かなり影響ありそうなので、使うときは注意した方がいい。
- 今回の結果に思い当たる節がある…。Dropoutを強くしたときに推定値が小さくなるなーと思ったことがあった。
- 実際に回帰問題でDropoutを使うかどうかは汎化性能との兼ね合いで決めるべき。UniformDropoutやGaussianDropoutを試してみるのもいいかも。MontecarloDropoutは計算量増加が許容されるなら強い。
詳細
Gistで公開しています。ブログ上だとスクロールしないといけないのでリンク先の方がたぶん見やすいです。
Effect of Dropout in regression task
他
参考文献
- Pitfalls with Dropout and BatchNorm in regression problems
https://towardsdatascience.com/pitfalls-with-dropout-and-batchnorm-in-regression-problems-39e02ce08e4d - 回帰でDropoutやBNを使ってはいけないという話を試してみた
https://github.com/ak110/regression-dropoutbn - GaussianDropout
http://www.cs.toronto.edu/~rsalakhu/papers/srivastava14a.pdf
https://keras.io/ja/layers/noise/ - UniformDropout
https://arxiv.org/pdf/1801.05134.pdf - Montecarlo Dropout
https://arxiv.org/pdf/1506.02142.pdf
分位点回帰を使ってLightGBMの推定値の分布と不確かさを評価する
分位点回帰を使った推定値の分布評価と不確かさ評価について気になっていたので試してみました。
記事タイトル及び検証ではLightGBMを使っていますが、他の手法でも同じ考え方を適用できるはずです。
以下の検証に関するコードはgithubにあげてあります。
quantile_regression_gbdt/quantile_regression.ipynb at main · statsu1990/quantile_regression_gbdt · GitHub
記事の概要
- 分位点回帰についての簡単な説明
- LightGBMでの検証
分位点回帰(Quantile Regression)について
通常の回帰問題では目的変数の平均値や中央値を推定するモデルを作ることが多いと思います。
分位点回帰では、1/4分位や3/4分位など指定の分位での目的変数の値(分位点)を推定するモデルを作れます。分位点での目的変数の値がわかると、目的変数の分布を推定することができるようになります。分布を推定できると推定値の不確かさを評価できるなど、実用上嬉しいことがたくさんあります。
よく使われる回帰問題と分位点回帰の違いは損失関数のみです。MSE Lossを使うと平均値、MAEを使うと中央値、Pinball Lossを使うと分位点を推定するモデルとなります。
Pinball Lossは全然複雑ではないのでcustom lossとして自分で作ることも簡単ですし、LightGBMではobjectiveとして用意されていたりするので、分位点回帰を使うハードルはかなり低いです。
詳細はこちらのサイト等を参照してください。
分位点回帰を使って、「その回帰予測どれぐらい外れるの?」を説明する - BASEプロダクトチームブログ
ピンボールロス(Pinball loss)の解説 – S-Analysis
QRNN ニューラルネットを用いた分位点回帰 - 学習する天然ニューラルネット
LightGBMでの検証
LightGBMでの分位点回帰の有効性を検証してみました。
データはKaggle House Pricesの学習データを使いました。Kaggle House Pricesは、部屋の広さ等の説明変数から家の販売価格を予測するタスクです。
House Prices - Advanced Regression Techniques | Kaggle
検証の概要
- LightGBMでの分位点回帰の実装
- 分位点の可視化
- 分位点の妥当性評価
- 推定誤差と分位点から算出した標準偏差の関係性の評価
検証の条件
- データを、49%学習データ、21%バリデーションデータ、30%テストデータに分割
- 目的変数はlog(家の販売価格)
- 説明変数は数値変数のみ使用(カテゴリ変数は削除)
- LightGBMのパラメータサーチはしない
- (0.05, 0.15, 0.25, 0.35, 0.45, 0.55, 0.65, 0.75, 0.85, 0.95)の分位点を推定するモデルを作成
LightGBMでの分位点回帰の実装
objectiveにquantileを指定し、alphaに分位を指定するだけで分位点回帰になります。
mdl = LGBMRegressor(objective='quantile', alpha=0.4)
複数の分位点を推定したい場合、分位ごとにモデルを作る必要があります。なお、NNだと1つのモデルで複数出力にできると思います。
quantiles = (0.05, 0.15, 0.25, 0.35, 0.45, 0.55, 0.65, 0.75, 0.85, 0.95) qr_models = [] for q in quantiles: mdl = LGBMRegressor(objective='quantile', alpha=q) mdl.fit(tr_x, tr_y) qr_models.append(mdl)
分位点の可視化
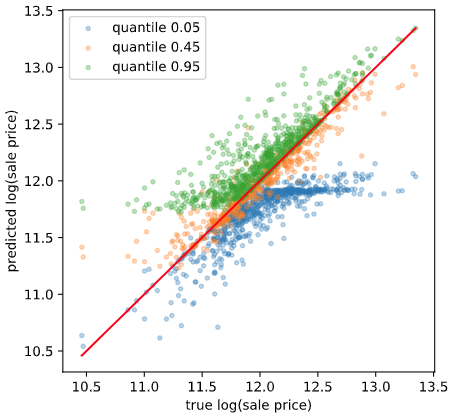
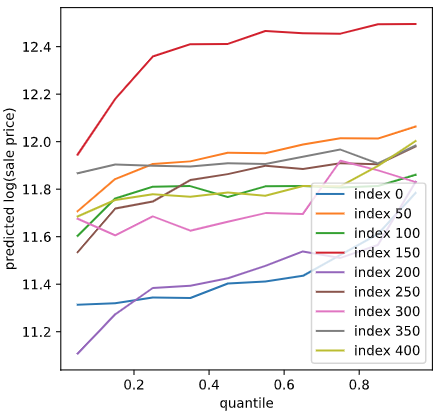
分位点をうまく推定できていれば、小さい分位での推定値は小さく、大きい分位での推定値は大きくなるはずです。可視化して確認してみます。
学習データ
テストデータ
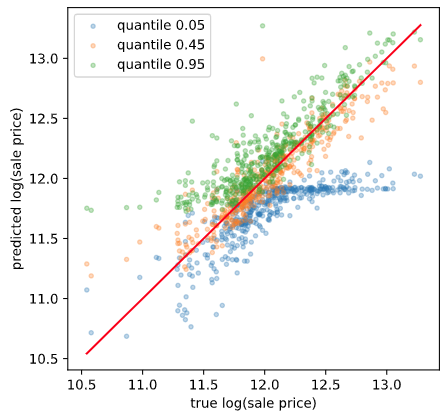
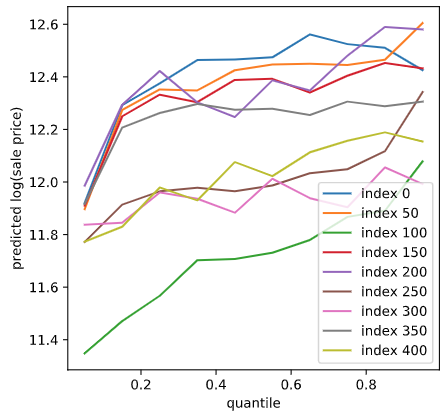
良い感じですね。基本的に分位が大きいほど推定値が大きくなっています。ただ、一部そうなっていないところもあります。原理的に多少の誤差はあるようです。
また、正解値が大きいときに分位0.05がサチっているように見える、正解値が小さいときに分位0.95がサチっているように見えるのですが、理由はわかりません。とりあえずスルーします。
分位点の妥当性評価
分位点を推定できるようになりましたが、推定した分位点が本当にその分位での目的変数の値なのか評価したいです。「指定した分位での目的変数の正解値」は普通わからないので、正解値と直接比較するような評価はできません。ここでは、分位点の定義に立ち戻って評価します。
分位点の定義より、「正解値が分位点以下になる確率」=「分位」となるはずです。そうなっているか可視化してみます。

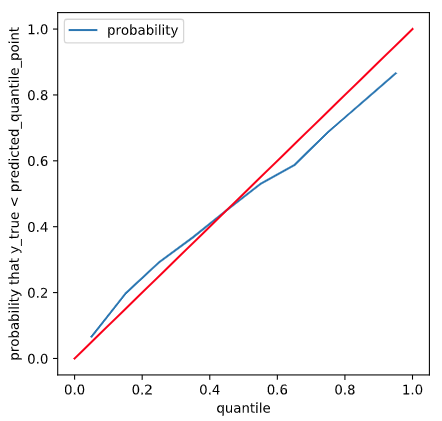
推定誤差と分位点から算出した標準偏差の関係性の評価
推定した分位点から、推定値の平均値と標準偏差を計算できます。正解値とこの平均値の差を推定誤差としたとき、推定値の標準偏差(=不確かさ)が大きいほど推定誤差も大きくなると考えられます。このような関係となっているか可視化して確認します。
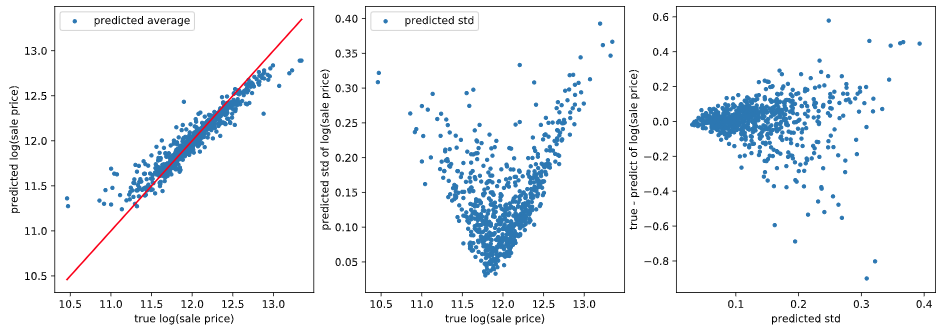
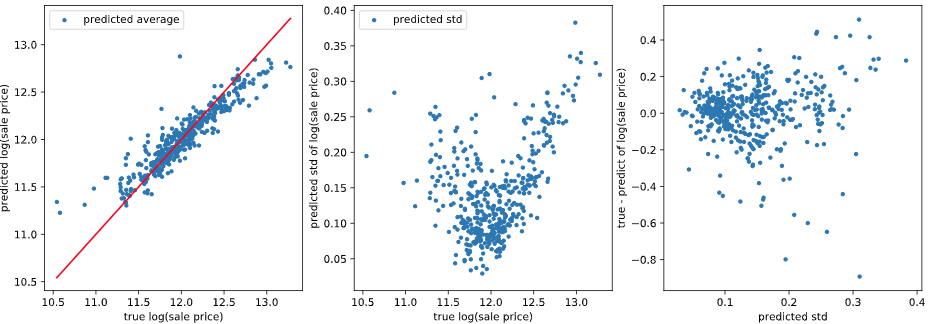
まとめ
- 分位点回帰について説明しました。
- LightGBMでの分位点回帰の実装方法について説明しました。
- Kaggle House Pricesデータを使って、分位点回帰で分位点を推定できていること、推定値の不確かさを評価できることを確認しました。
Windows10でAnacondaを使ったVS CodeのPython開発環境設定
いつも忘れるので自分用のメモです。
準備
VS Codeの設定
settings.jsonの設定
pythonを動かせるようにするための設定。このサイトを参考にした。
Windows + Anaconda3 + Visual Studio Code でPython開発環境 - Qiita
{ // 拡張機能のロード時にターミナルでPython環境をアクティブにする。 "python.terminal.activateEnvInCurrentTerminal": true, // Anaconda仮想環境のpython.exeを指定 "python.pythonPath": "C:\\Users\\[user name]\\Anaconda3\\envs\\trade\\python.exe", // condaコマンドを指定 "python.condaPath": "C:\\Users\\[user name]\\Anaconda3\\condabin\\conda.bat", // 仮想環境を指定 "python.venvPath": "C:\\Users\\[user name]\\Anaconda3\\envs\\trade", "python.autoComplete.extraPaths": [ "C:\\Users\\[user name]\\Anaconda3\\envs\\trade\\Lib\\site-packages", ], }
tasks.jsonの設定
デバッグできるようにするための設定。
このサイトのとおり設定する。
Python環境構築(Anaconda + VSCode) @ Windows10 【2020年1月版】 - Qiita
pep8に関する設定
autopep8, flake8を使う。
[python PEP8] VSCodeでautopep8とflake8を適用する | trelab
VSCodeのPython開発環境でpylintの代わりにflake8を導入し自動整形を設定する - Qiita
VSCodeのPython開発環境でpylintの代わりにflake8を導入し自動整形を設定する - Qiita
autopep8の文字数/1行の制限を緩くする。
Pythonのフォーマットで勝手に改行しないようにする | TIL
以上
YOTO(YOU ONLY TRAIN ONCE)を不均衡データ対策の損失関数に適用して画像分類してみた
この記事は、YOTO(YOU ONLY TRAIN ONCE)の雰囲気を掴むことを目的として、不均衡データ対策の損失関数にYOTOを適用して画像分類してみた記録です。
YOTOを使うことで、1つのモデルでMajorクラスの性能が良いモデル or Minorクラスの性能が良いモデルをテスト時に選択できました。
検証に使ったコードはgithubにあります。
GitHub - statsu1990/yoto_class_balanced_loss: Unofficial implementation of YOTO (You Only Train Once) applied to Class balanced loss
記事の概要
YOTO(YOU ONLY TRAIN ONCE)について
- ICLR2020でGoogleから発表されたDeep learningに関する技術。
- YOTOを適用したモデルは、モデルに損失関数のハイパーパラメータを入力できるようになり、推論時にハイパーパラメータの値を変えられる。普通であればハイパーパラメータの値毎に異なるモデルが必要となるが、YOTOでは1つのモデルで異なるハイパーパラメータに対応できるようになる。
- 論文中では画像圧縮タスクとstyle transferタスクに適用されている。YOTOを使うことで、1つのモデルで圧縮~画質の調整、style強度の調整ができるようになっていた。

Style transferでのYOTOのモデル構造
(Google AI Blog: Optimizing Multiple Loss Functions with Loss-Conditional Trainingより引用)
Style transferでのスタイル強度の調整(上:YOTO、下:固定ハイパーパラメータでそれぞれモデル学習)
https://openreview.net/pdf?id=HyxY6JHKwrより引用
- ICLR2020でGoogleから発表されたDeep learningに関する技術。
不均衡データ対策の損失関数へのYOTOの適用
- この記事ではYOTOを不均衡データでの画像分類タスクに適用してみた。
- 不均衡データでの分類タスクでは、クラス毎のデータ数に偏りがある。不均衡データをそのまま学習するとデータ数が多いクラス(Majorクラス)が優先的に学習され、データ数の少ないクラス(Minorクラス)の推定精度が低くなることがある。
- 損失関数を工夫することでMinorクラスの推定精度を上げることができる。この記事ではClass Balanced Lossを使う。Class Balanced Lossには、「Minorクラスをどれだけ優先するか」というハイパーパラメータβがある。βが小さければMajorクラスが優先され、βが大きければMinorクラスが優先される。YOTOとClass Balanced Lossを組み合わせることで、1つのモデルでMajorクラスの性能が良いモデル or Minorクラスの性能が良いモデルをテスト時に選択できるようになるはず。
- この記事ではYOTOを不均衡データでの画像分類タスクに適用してみた。
- 検証
- YOTOとClass Balanced Lossを組み合わせることで、1つのモデルでMajorクラスの性能が良いモデル or Minorクラスの性能が良いモデルをテスト時に選択できるようになるか検証した。
- Cifar10とCifar100を不均衡データにしたデータセットを使った。モデルにはResNet18を使った。
- 1つのモデルでMajorクラスの性能が良いモデル or Minorクラスの性能が良いモデルをテスト時に選択できること(Minorクラスの優先度を変えた推論をできること)を確認した。
- ハイパーパラメータ固定で学習したモデルとYOTOで学習したモデルの性能を比較すると、同じハイパーパラメータでも性能は完全には一致しなかった。Majorクラスの分類精度は若干下がり、Minorクラスの分類精度は向上した。同じモデルサイズであれば性能が下がるのは論文のとおりなので納得だが、Minorクラスの分類精度が向上したのは意外だった。ハイパーパラメータ固定だと学習が不安定になるケースでも、YOTOだと安定して学習できて性能上がることがあるのかも(※個人的な推測です)。
- YOTOとClass Balanced Lossを組み合わせることで、1つのモデルでMajorクラスの性能が良いモデル or Minorクラスの性能が良いモデルをテスト時に選択できるようになるか検証した。
YOTO (YOU ONLY TRAIN ONCE)について
YOTOはICLR2020でGoogleから発表されたDeep learningに関する技術です。論文のタイトルは"YOU ONLY TRAIN ONCE: LOSS-CONDITIONAL TRAINING OF DEEP NETWORKS"で、YOTOとはYOU ONLY TRAIN ONCEの略です。Object detectionで使われるYOLO(You Only Look Once)のパロディ的な名称ですね。カッコエエ。
論文:https://openreview.net/pdf?id=HyxY6JHKwr
Google AI Blog:Google AI Blog: Optimizing Multiple Loss Functions with Loss-Conditional Training
YOTOの概要
ざっくり概要を説明します。Google AI Blogにコンセプトが良くまとまっているので、詳しくはそっちを見てください。
Deep learningで使われる損失関数にはハイパーパラメータを含むものがあり、ハイパーパラメータの値が異なると学習されたモデルの性能や特徴が変わります。例えば、画像圧縮モデル(画像を入力すると合宿した画像を出力する)を学習するときには、損失関数には「ファイルサイズと画質のどちらを優先するか」というハイパーパラメータが含まれます。次式のような損失関数であれば、λがそのハイパーパラメータです。
圧縮サイズを優先するモデルと画質を優先するモデルが欲しければ、ハイパーパラメータを変えて学習させ、別々に2つのモデルを作る必要があります。
YOTOを適用したモデルでは、損失関数のハイパーパラメータを入力として受け取り、そのハイパーパラメータに対応した出力を出せるようになります。つまり、ハイパーパラメータ毎にモデルを用意する必要がないので学習時間や容量が減って嬉しいです。また、推論時にハイパーパラメータの値をいじって出力を調整できるのも嬉しいです。

https://openreview.net/pdf?id=HyxY6JHKwrより引用
論文で紹介されていたStyle transferでは、下図のように1つのモデルでStyle強度を調整できるようになっています。
https://openreview.net/pdf?id=HyxY6JHKwrより引用
上記の画像圧縮の例とすると、従来とYOTOは以下のような違いがあります。
従来
- ファイルサイズ優先させた損失関数を使って学習したモデル
に画像
を入力し、ファイルサイズ優先の圧縮画像
を出力する。
- 画質優先させた損失関数を使って学習したモデル
に画像
- ファイルサイズ優先させた損失関数を使って学習したモデル
YOTO
- YOTOを使って学習したモデル
に画像
を入力し、ファイルサイズ優先の圧縮画像
- YOTOを使って学習したモデル
を入力し、画質優先の圧縮画像
- YOTOを使って学習したモデル
YOTOのモデル構造
YOTOのモデル構造は下図のとおりです。
(Google AI Blog: Optimizing Multiple Loss Functions with Loss-Conditional Trainingより引用)
簡単に説明しておきます。
- Main network:従来のモデル構造。例えば、画像分類だったらResNet、SegmentationだったらUNetなど。
- α:損失関数のハイパーパラメータ。学習時には指定した値域内からランダムサンプリングします。推論時は使いたい値に設定する。
- Conditioning network:αを入力とし、σとμという量を出力するNeural Network。Main networkと一緒に学習する。論文ではσ、μそれぞれを出力するMLP(multi layer perceptron)が使われていた。
- Conditioning networkとMain networkのつなぎ:Conditioning networkの出力σとμをFiLMという手法でMain networkに入れて、αによる影響をMain networkに組み込む。
- FiLM:Feature-wise Linear Modulationの略。下図(βがμ、γがσに対応)の方法でσとμをMain networkに入れる。style transferで使われるAdaINと似た手法である。σとμの直前のBatch Normalization layerでaffine変換をしないようにするのを忘れないように注意する。

https://arxiv.org/pdf/1709.07871.pdfより引用
https://arxiv.org/pdf/1709.07871.pdfより引用
YOTOの学習と推論手順
学習と推論の手順を説明しますが、オフィシャルな実装が公開されていないので、正確ではないところがあるかもしれません。
学習の準備
- ハイパーパラメータの値域とサンプリング方法を決める。[0,1]の範囲で一様分布からサンプリングなど。[1e-5,1]の範囲で対数一様分布からサンプリングなど。
- ハイパーパラメータの値域とサンプリング方法を決める。[0,1]の範囲で一様分布からサンプリングなど。[1e-5,1]の範囲で対数一様分布からサンプリングなど。
学習手順
- バッチサイズの数だけInputを生成。バッチサイズの数だけハイパーパラメータをサンプリング(バッチごとに1つのハイパーパラメータでもいいかも)。
- Inputとサンプリングしたハイパーパラメータをモデルに入力し、Lossを計算。モデルの重みを更新。
- 1~2を繰り返す。
- バッチサイズの数だけInputを生成。バッチサイズの数だけハイパーパラメータをサンプリング(バッチごとに1つのハイパーパラメータでもいいかも)。
推論手順
- Inputと任意のハイパーパラメータ値をモデルに入力し、出力を得る。
- Inputと任意のハイパーパラメータ値をモデルに入力し、出力を得る。
その他メモ
- 論文によると、モデルサイズが小さい場合、ハイパラ固定のモデルよりも性能が下がるらしい。モデルサイズを大きくしていくとその差が小さくなる。
不均衡データ対策の損失関数 Class Balanced Loss
後述する検証で使う不均衡データ対策の損失関数であるClass Balanced Lossについて説明します。
論文:[1901.05555] Class-Balanced Loss Based on Effective Number of Samples
日本語ブログ:不均衡データを損失関数で攻略してみる - Qiita
不均衡データをそのまま学習に使うと、データ数が多いクラス(Majorクラス)が重点的に学習され、データ数が少ないクラス(Minorクラス)に関する性能が悪化することが知られており、いろいろな対策が考えられています。対策の1つが損失関数の工夫で、データ数の逆数でLossの寄与率を重みづけ、Focal Lossなどがあります。
Class Balanced Lossは、データ数の逆数でLossの寄与率を重みづけの亜種です。
説明のために、クラス数がCである分類問題について考えます。
通常のSoftmax Cross Entropy Lossは次式のようになります。
ただし、iはバッチ内のサンプル番号、はサンプルiの正解ラベル、
はラベルmに対応するソフトマックス出力です。
データ数の逆数でLossの寄与率を重みづけしたSoftmax Cross Entropy Lossは次式のようになります。
ただし、はラベルmのデータ数です。式からわかるようにデータ数の少ないクラスほどLossへの寄与率
が大きくなるため、Minorクラスが重点的に学習されます。
Class balanced Softmax Cross Entropy Lossは次式のようになります。
詳しい意味は上述のブログや論文を参照してください。大事なポイントは以下のとおりです。
- データ数によってLossの寄与率
が決まる。データ数が少ないほど寄与率は大きくなる。
- Loss(損失関数)のハイパーパラメータはβのみ。
- βの値域は[0,1]であり、β=0のときはCE、β=1のときはICEと一致する。その間の値のときはCEとICEの間のような感じ。すなわち、β=0のときは不均衡を考慮せずに学習し(Majorクラスを重点的に学習する)、β=1のときはMinorクラスを重点的に学習すると言えます。
ちょうどいいβを選択すると性能がよくなる。
Class balanced Lossではβのみがハイパーパラメータなので、後述する検証ではβを対象としてYOTOの学習をします。
検証
YOTOがどんなもんなのか感覚を掴むため、YOTOをClass balanced lossに適用してみました。ゴールは、YOTOで学習したモデルでClass balanced lossのβを動かし、MajorクラスとMinorクラスで分類性能が変わっていく様子を見ることです。Class balanced lossを選んだのは、Style transferとかより簡単そうだったからです。
目的
- YOTOを使って、1つのモデルだけでMajorクラスの性能が良いモデル or Minorクラスの性能が良いモデルをテスト時に選択できるようにする。
概要
- 不均衡データセットの画像分類タスクを対象とする。
- ResNet18とClass balanced lossを組み合わせたモデルを以下のケースで学習させ、Majorクラス、Minorクラス及び全クラスでのAccuracy等を比較する。
- YOTOでβを調整できるようにしたモデル
- βを固定して学習したモデル
- YOTOでβを調整できるようにしたモデル
条件
データセット
- Case 1
- Cifar 10でクラス毎のデータ数を不均衡にしたもの。trainデータではクラス0,2,4,6,8を各5000枚、クラス1,3,5,7,9を各250枚とした。testデータはデフォルト枚数(各クラス1000枚)のまま。
- Cifar 10でクラス毎のデータ数を不均衡にしたもの。trainデータではクラス0,2,4,6,8を各5000枚、クラス1,3,5,7,9を各250枚とした。testデータはデフォルト枚数(各クラス1000枚)のまま。
- Case 2
- Cifar 100でクラス毎のデータ数を不均衡にしたもの。trainデータではクラス0~49を各500枚、クラス50~99を各25枚とした。testデータはデフォルト枚数(各クラス100枚)のまま。
- Cifar 100でクラス毎のデータ数を不均衡にしたもの。trainデータではクラス0~49を各500枚、クラス50~99を各25枚とした。testデータはデフォルト枚数(各クラス100枚)のまま。
- Case 3
- Cifar 100でクラス毎のデータ数を不均衡にしたもの。trainデータではクラス0~49を各500枚、クラス50~99を各50枚とした。testデータはデフォルト枚数(各クラス100枚)のまま。
- Cifar 100でクラス毎のデータ数を不均衡にしたもの。trainデータではクラス0~49を各500枚、クラス50~99を各50枚とした。testデータはデフォルト枚数(各クラス100枚)のまま。
- Case 1
モデル
学習
- epoch数100、バッチサイズ128、SGD(momentum=0.9, weight decay=5e-4)、学習率0.1(epoch 50、85で0.1倍)
- YOTOでのβのサンプリング範囲は[0.9, 0.99999]で、1 - βの対数一様分布からサンプリング。
- epoch数100、バッチサイズ128、SGD(momentum=0.9, weight decay=5e-4)、学習率0.1(epoch 50、85で0.1倍)
実装
github参照
GitHub - statsu1990/yoto_class_balanced_loss: Unofficial implementation of YOTO (You Only Train Once) applied to Class balanced loss
結果
Case 1
Cifar 10で、trainデータのクラス0,2,4,6,8を各5000枚、クラス1,3,5,7,9を各250枚にしたデータセットのテスト結果は下図のとおりです。結果から以下のことがわかります。
- YOTOの結果より、1-βが大きい(βが大きく、Majorクラスが重点的に学習される)ときにはMajorクラスの分類精度が高く、1-βが小さい(βが小さく、Minorクラスが重点的に学習される)ときにはMinorクラスの分類精度が高くなった。
狙いどおり、テスト時にβを変えることで、1つのモデルでMajorクラスの性能が良いモデル or Minorクラスの性能が良いモデルを選択できるようになった。 - 1-βが大きいときYOTOは性能が低い。これは論文と一緒で、モデルが小さいことが原因と思われる。
- 1-βが小さいときYOTOの性能が高い。これは不思議で原因はよくわからない。1-βが大きいときと同じで、性能が下がると思っていた。1-βが大きいときはMajorクラスとMinorクラスの重みの比が20倍近くになるので、固定ハイパラだと学習が不安定になるが、YOTOだと安定するとかあるのかもしれない。

参考までに学習曲線をのせておきます。




Case 2
Cifar 100で、trainデータのクラス0~49を各500枚、クラス50~99を各25枚としたデータセットでのテスト結果は下図のとおりです。Case 1と同じ傾向となっています。

Case 3
Cifar 100で、trainデータのクラス0~49を各500枚、クラス50~99を各50枚としたデータセットでのテスト結果は下図のとおりです。Case 1, 2と同じ傾向となっています。ただし、βが小さいときの性能低下が大きいですね。

結果まとめ
- Case1~3のすべてで、YOTOを使うことで1つのモデルでMajorクラスの性能が良いモデル or Minorクラスの性能が良いモデルをテスト時に選択できた。
- Class balanced lossのβが大きいとき(Minorクラスの重み大)に固定ハイパラより性能がかなり良くなった。理由はわからないが、YOTOによって不安定な学習が安定したとかあるのかもしれない。
まとめ
- YOTOの概要を説明した。
- Class balaned lossの概要を説明した。
- 不均衡データでの画像分類タスクにおいて、YOTOをClass balanced lossを組み合わせることで、1つのモデルでMajorクラスの性能が良いモデル or Minorクラスの性能が良いモデルをテスト時に選択できた。
- 基本的に固定ハイパラよりYOTOのモデルは性能が落ちるが、性能が上がるケースもあった。原因はわからないが、不安定な学習を安定させられる効果がYOTOにはあるのかもしれない。
思ったこと
- 1つのモデルでアンサンブルできそう。
- ハイパーパラメータサーチに使えるかと思ってたけど、固定ハイパラと不一致がそれなりにあるので難しそう。Focal lossで試したけどうまくいかなかった。
Kaggleのコンペ参加記録まとめ
Kaggleのコンペ参加記録のまとめです。(自分用)
Kaggleとは
- Kaggle: Your Machine Learning and Data Science Community
- データサイエンス・機械学習オンラインコンペティションサイト。
- 企業や研究機関がタスクを投稿し、世界中のデータサイエンティスト・機械学習エンジニアがタスクを解くモデル作り、その精度を競う。

Kaggleアカウントプロフィール
画像認識
Kuzushiji Recognition
- タスク
- 本の画像からくずし字の位置を検出し、文字を分類する。
- Kuzushiji Recognition | Kaggle
- 本の画像からくずし字の位置を検出し、文字を分類する。
- 順位
- 15位/293チーム(上位5%)
- 15位/293チーム(上位5%)
- 参加記録
- My Solution
Bengali.AI Handwritten Grapheme Classification
- タスク
- 手書きのベンガル語1文字の画像から、どの文字が書かれているか分類する。
- Bengali.AI Handwritten Grapheme Classification | Kaggle
- 手書きのベンガル語1文字の画像から、どの文字が書かれているか分類する。
- 順位
- 24位/2059チーム(上位1%)
- 24位/2059チーム(上位1%)
- 参加記録
- My Solution
Understanding Clouds from Satellite Images
- タスク
- 衛星画像から、特定の形状の雲の位置をセグメンテーションする。
- Understanding Clouds from Satellite Images | Kaggle
- 衛星画像から、特定の形状の雲の位置をセグメンテーションする。
- 順位
- 167位/1538チーム(上位11%)
- 167位/1538チーム(上位11%)
- 参加記録
- My Solution
自然言語処理
Google QUEST Q&A Labeling
- タスク
- QAサイトの質問・回答の文書から、人が主観的にどう感じたかを予測する。
- Google QUEST Q&A Labeling | Kaggle
- QAサイトの質問・回答の文書から、人が主観的にどう感じたかを予測する。
- 順位
- 61位/1571チーム(上位4%)
- 61位/1571チーム(上位4%)
- 参加記録
- My Solution
TensorFlow 2.0 Question Answering
- タスク
- 質問に対して、回答を含む文書のどの位置が回答かを予測する。
- TensorFlow 2.0 Question Answering | Kaggle
- 質問に対して、回答を含む文書のどの位置が回答かを予測する。
- 順位
- 128位/1233チーム(上位10%)
- 128位/1233チーム(上位10%)
- 参加記録
- 未作成
- 未作成
- My Solution
- xxx
- xxx
ReZeroの収束性と精度について画像認識(Cifar100)で検証した記録
ReZeroという最近提案されたDeep learning関連の手法を画像認識(Cifar100)で試したのでその記録です。
結論としては、Cifar100での画像認識では効果なかったです。(なんかミスしている可能性もなくはない)
本記事の概要
- ReZeroの概要
- ReZeroの実装
- ReZeroの検証
- まとめ
ReZeroの概要
ReZeroは"ReZero is All You Need: Fast Convergence at Large Depth"という論文で提案された手法です。(〇〇 is All You Needって言ってみたい…)
[2003.04887] ReZero is All You Need: Fast Convergence at Large Depth
詳細は論文を読んでもらうとして、ここでは論文の主張について概要を簡単に説明します。
ReZeroとは
Deep learningでは、深い層数で学習するために正規化(BatchNorm、LayerNormなど)やResidual connection(ResNetなどで使われるやつ)が使われます。これらを使わないと層数が多い場合には勾配消失等の問題によりうまく学習できません。
ReZeroは、従来の正規化やResidual connectionの代わりとして使え、収束性が上がるらしいです(ただし、BatchNormに関してはReZeroのアプローチを補完するらしい。よくわからん。)。
ReZeroの構造は簡単で、Residual connectionにResidual weight αという学習可能パラメータを追加した形となっています。αの初期値は0にします。これを以下のように正規化やResidual connectionの代わりに使います。



効果
論文によると、以下の効果があるそうです。
- より深い層数のアーキテクチャの学習が可能となる。10000層の全結合ネットワークや100層以上のTransformerを学習できた。
- 収束性が早くなる。Transformerでは、enwiki8ベンチマークで1.2BPBに56%速く到達した。ResNetでは、Cifar 10で85%の精度に32%速く到達した。ただし、Cifar 10での検証結果は、なぜかおまけみたいな扱いで少ししか触れられていません。
実装
私はpytorchで以下のように実装しました。簡単で良い。
import torch import torch.nn as nn from torch.nn.parameter import Parameter class ReZeroShortcut(nn.Module): def __init__(self, alpha=0.0): super(ReZeroShortcut, self).__init__() self.alpha = Parameter(torch.ones(1) * alpha) def forward(self, shortcut, x): return shortcut + self.alpha * x
GitHub - statsu1990/ReZero-Cifar100: Verification of ReZero ResNet on cifar 100 dataset
検証
Cifar10
論文ではCifar10で以下の結果が出ています。
- ResNet56のresidual connectionをすべてReZero connectionに置き換える。
- validation errorが7.37±0.06 %から6.46±0.05%に向上した。
- validationエラーが15%未満になるepoch数が32±14%減少した。
非公式ですがCifar10での実験結果をgithubで見つけました。比較の仕方がよくわからないところもあるけど、ReZeroの効果があるようには見えない。。
GitHub - fabio-deep/ReZero-ResNet: Unofficial pytorch implementation of ReZero in ResNet
Cifar100
さて、私はCifar100でPreAct-ResNetを学習させ、ReZeroの有無で精度と収束性がどう変わるか検証しました。検証に使ったコードはこちらです。
GitHub - statsu1990/ReZero-Cifar100: Verification of ReZero ResNet on cifar 100 dataset
目的
- ReZeroの有無による精度と収束性の違いを確認する。
検証方法・条件
以下の条件で学習させ、ReZero有無での精度と収束性を比較します。
- データ
- cifar 100
- cifar 100
- モデル
- ベースモデル:PreAct ResNet 18, 50
[1603.05027] Identity Mappings in Deep Residual Networks - モデル with ReZero:ベースモデル中のresidual connectionをすべてReZero connectionに変えたもの。residual weight αの初期値は0。
- モデル with ReZero (個人的改良版):ベースモデル中のresidual connectionをすべてReZero connectionに変えたもの。αの代わりにtanh(α)を使用(αの初期値は0)。αが異常に大きくなることを避けるため、値域を限定する目的でtanh(α)としてみた。
- ベースモデル:PreAct ResNet 18, 50
- 学習方法
- Cross entropy loss
- SGD, 学習率0.1 (60、120、160epochで学習率を0.2倍し小さくする)、epoch数200、バッチサイズ128
- Data augmentation (random flip, random shift scale rorate)
- Cross entropy loss
検証結果
(2020/3/30修正:rezero preact-resnet18の結果を少し修正)
学習曲線がこちらです。精度も収束性も改善していません。
PreAct ResNet 18


PreAct ResNet 50


学習完了後のモデル with ReZeroのResidual weight αの値は以下のとおりです。stageは下表のlayer nameのconv2_x~conv5_xに、blockは3×3,64や1×1,64に対応しています。
概ね-2~2程度の値をとるようです。たまに絶対値が大きい値がありますね。



まとめ
- 深い層でも学習できるようになる&学習の収束性を上げることができるというReZeroの概要を説明しました。
- ReZeroはCifar100 + Preact-ResNetでは効果がなかったです。なんなら逆に収束性も精度も悪くなりました。なんかやり方間違っているのかな。誰か間違いに気づいたら教えてください。
- Deep Learningの論文の再現性って闇深い。ちゃんと検証してみたら効果なかったわ、みたいな論文が定期的に出ている気がする。
Kaggle Bengali Classificationコンペに参加した記録
KaggleのBengali.AI Handwritten Grapheme Classificationコンペに参加して24位(2059チーム中)でソロ銀メダルを取れました。ついでにkaggle expertになりました。
以下ではその記録についてまとめます。
本記事の概要
- コンペ概要
- 私の取り組み
- 興味深かった上位ソリューション
- 感想
コンペ概要

タスク概要
データ
- 入力データ:手書きのベンガル語1文字の画像データ。
- 予測対象データ:書式素、母音、子音のラベル。
- 学習データ数200840。 Bengali - Quick EDA | Kaggle
- 入力データ:手書きのベンガル語1文字の画像データ。
予測性能の評価方法
- 書式素、母音、子音それぞれのマクロリコールを0.5、0.25、0.25で重みづけ平均したものが評価値。
- 書式素、母音、子音それぞれのマクロリコールを0.5、0.25、0.25で重みづけ平均したものが評価値。
スタンダードな解法
- 解法(1):CNN系統の画像分類器で画像から書式素(169クラス)、母音(11クラス)、子音(7クラス)それぞれのラベルを予測する。
- 解法(2):CNN系統の画像分類器で画像から文字のラベル(1295クラス)を予測する。学習データ中には書式素、母音、子音の組合せが1295パターンあったため1295クラス。ただし、実際のベンガル語では当然他の組合せも存在する(169×11×7パターン?)。
- 解法(1):CNN系統の画像分類器で画像から書式素(169クラス)、母音(11クラス)、子音(7クラス)それぞれのラベルを予測する。
大規模なshake
- このコンペでは大規模なshakeが発生し、一部のトップ層を除いて、Public LBとPrivate LBの順位が激しく入れ替わった。原因は、学習データに含まれていない書式素、母音、子音の組合せがテストデータに多く含まれていたことである。上記の解法(2)のような学習データ中に存在している組合せに適合する方法を採用していた人は、Public LBではいいスコアであったが、Private LBでは大幅に下落した。トップ層は学習データに含まれている組合せに適合させつつ、見えていない組合せもケアする工夫をしていたので、Public LBでもPrivate LBでもいいスコアであった。ほんますごい。
- 僕はこの恩恵にあずかってshakeupし、銀メダルになった。Public LBではメダル圏外で完全にあきらめていたので心底びっくりした。
https://www.kaggle.com/c/bengaliai-cv19/leaderboard
- このコンペでは大規模なshakeが発生し、一部のトップ層を除いて、Public LBとPrivate LBの順位が激しく入れ替わった。原因は、学習データに含まれていない書式素、母音、子音の組合せがテストデータに多く含まれていたことである。上記の解法(2)のような学習データ中に存在している組合せに適合する方法を採用していた人は、Public LBではいいスコアであったが、Private LBでは大幅に下落した。トップ層は学習データに含まれている組合せに適合させつつ、見えていない組合せもケアする工夫をしていたので、Public LBでもPrivate LBでもいいスコアであった。ほんますごい。
私の解法
私の解法は以下のとおりです。基本は上記の解法(1)で、工夫した点は評価値であるマクロリコールに最適化するために実数値遺伝的アルゴリズムを使ったところです。
コード
概要
Discussionにもsolutionをあげましたが、ここでは日本語をのせておきます。(下手な英語だから理解してもらえているのかかなり不安。。笑)
https://www.kaggle.com/c/bengaliai-cv19/discussion/136064
私のソリューションでは、単純なアンサンブルモデルと、マクロリコールを最大化するための後処理を使いました。後処理では、モデルが出力したlogitにバイアスを足します。後処理が私のスコアの多くを占めており、後処理なしではメダル圏外でした。
Inference Label
まず、DL modelでlogitを出力します。後処理として、logitにバイアスを加えます。それをargmaxしたものを推定ラベルとします。

Model
モデルは5つのモデルをアンサンブルしたものです。学習にはトレーニングデータをすべて使いました。私の時間と計算資源が限られていたので、クロスバリデーションをほとんどできていません。
model 1, 2, 3, 4
- Seresnext50_32x4d (pretrained model using imagenet)
- image size 128x128
- Three linear head (output is grapheme root logit(168), Vowel diacritic logit(168), Consonant diacritic logit(168))
- Mish activation, Drop block
- Cross Entropy Loss
- AdaBound
- 以下のパラメータをモデル毎に変える
- Manifold mixup (alpha, layer), ShiftScaleRotate, Cutout
- Manifold mixup (alpha, layer), ShiftScaleRotate, Cutout
- Seresnext50_32x4d (pretrained model using imagenet)
model 5
- Seresnext50_32x4d (pretrained model using imagenet)
- image size 137x236
- Three linear head (output is grapheme root logit(168), Vowel diacritic logit(168), Consonant diacritic logit(168))
- Mish activation, Drop block
- Cross Entropy Loss
- AdaBound
- Manifold mixup (alpha, layer), ShiftScaleRotate, Cutout
- Seresnext50_32x4d (pretrained model using imagenet)
後処理のバイアスの計算
モデルはCross Entropy Lossで学習されているので、一般的にマクロリコールを最大化しません。そこで、私はlogitに加えることでマクロリコールを最適化するようなバイアスを使うことを考えました。最適なバイアスを以下の手順で計算しました。

- 学習データ全てに対してlogitを計算する。
- 実数値遺伝的アルゴリズムでマクロリコールを最大化するバイアスを計算する。
- データ拡張した学習データ全てに対してlogitを計算する。
- 実数値遺伝的アルゴリズムでマクロリコールを最大化するバイアスを計算する。
- 上記のバイアスを平均し、最終的なバイアスとする。
テストデータの推定では、学習データで算出したバイアスを使います。

実数値遺伝的アルゴリズムについてはこちらのページを参考にしてください。
st1990.hatenablog.com
Score (Public LB / Private LB)
- model1(wo bias) : 0.9689 / 0.9285
- model2(wo bias) : 0.9680 / 0.9270
- model3(wo bias) : 0.9691 / 0.9317
- model4(wo bias) : 0.9681 / 0.9243
- model5(wo bias) : 0.9705 / 0.9290
- ensemble1~5(wo bias) : 0.9712 / 0.9309
- ensemble1~5(with bias) : 0.9744 / 0.9435
興味深かった上位のソリューション
- 学習データに存在しない書式素・母音・子音の組み合わせに対応するための工夫。
- Arcfaceを使って学習データに存在しない組み合わせを検知し、存在するしないで別のモデルを使っていた。https://www.kaggle.com/c/bengaliai-cv19/discussion/135982
- 存在しない組み合わせの場合はCycle GANで既存のベンガル語フォントに変換。変換したものをベンガル語フォントの分類モデルにいれてクラス分類していた。既存のベンガル語フォントは外部データを使用。https://www.kaggle.com/c/bengaliai-cv19/discussion/135984
- マクロリコールのハック。https://www.kaggle.com/c/bengaliai-cv19/discussion/136021
- Arcfaceを使って学習データに存在しない組み合わせを検知し、存在するしないで別のモデルを使っていた。https://www.kaggle.com/c/bengaliai-cv19/discussion/135982
上位はかなり工夫しててソリューションみるのも楽しかった。
まとめ
https://www.kaggle.com/c/bengaliai-cv19/discussion/136030
感想
- パラメータチューニングやモデルの構造など細かいところに時間をとってしまい、問題の特性を踏まえた大局的な取り組みができなかったのが反省。評価値について考察し、それに最適化させる方法を考えられたのは良かった。
- 今回のコンペの上位ソリューションは発想が素晴らしかった。問題についてよく考えて人と違う発想をしないと勝てないってことがよくわかった。